۱۰ اشتباه مرگبار در مجازیسازی که کارایی سرورهای HP را نابود میکند
مقدمه
در دنیای فناوری امروز، مجازیسازی عنصر کلیدی طراحی زیرساختهای محاسباتی به شمار میرود. سازمانها بر اساس Hypervisor و سرورهای فیزیکی قدرتمند خود، دهها تا صدها ماشین مجازی را برای اجرای سرویسهای حیاتی پیادهسازی میکنند. اما تجربیات عملی در پروژههای بزرگ نشان میدهد که ضعف در پیکربندی لایههای زیربنایی، بیشترین سهم را در کاهش کارایی، ایجاد Bottleneck و افت پایداری سیستمها دارد؛ حتی در سرورهای پیشرفته و نسلهای جدید مانند HPE ProLiant Gen10/Gen11.
در این مقاله جامع، سه ستون حیاتی کارایی زیرساخت—Hypervisor، معماری NUMA و Firmware—بهصورت دقیق تحلیل شده و نقش سرورهای HP در این حوزه بررسی میشود.
1. پیکربندی Hypervisor و اثرات حیاتی آن بر عملکرد زیرساخت
Hypervisor مسئول مدیریت Threadهای ماشینهای مجازی و تخصیص منابع پردازنده و حافظه به آنهاست. کوچکترین خطا در طراحی یا Allocation میتواند منجر به کندی محسوس سرویسها شود؛ بهویژه در محیطهای سنگین با بار کاری بالا.
1.1. Overcommitment؛ مشکل رایج اما نادیدهگرفتهشده
Overcommitment زمانی رخ میدهد که مجموع vCPUهای تخصیصدادهشده از تعداد هستههای فیزیکی بیشتر شود. با اینکه Hypervisorها اجازه Overcommit را میدهند، اما:
-
افزایش شدید CPU Contention
-
افزایش زمان CPU Ready
-
ایجاد Queue در Scheduler
-
Co-Stop برای VMهای Multi-vCPU
میتواند عملکرد را بهشدت کاهش دهد.
در پروژهای با ۳۰ سرور مختلف، تنها با بهینهسازی نسبت vCPU/Core، کارایی 35 تا 70 درصد افزایش یافته بدون آنکه سختافزار ارتقاء یابد.
1.2. Hyperthreading و برداشت اشتباه در طراحی vCPU
Hyperthreading در پردازندههای Intel (و SMT در AMD) باعث میشود سیستم از یک هسته فیزیکی دو Thread بسازد. اما باید دقت کرد:
-
هر ۲ Thread مربوط به یک هسته فیزیکی هستند
-
عملکرد آنها برابر دو Core واقعی نیست
-
اشتباه در محاسبه باعث فشار بر Scheduler میشود
در VMware ESXi، اشتباه گرفتن Logical Thread با Physical Core یکی از عوامل اصلی افزایش CPU Ready است.
1.3. VMهای بزرگ (Monster VM) و اثر منفی آنها بر Scheduling
ساختن ماشینهایی با ۱۲، ۲۴ یا ۳۲ vCPU بدون نیاز واقعی، باعث:
-
افزایش Co-Stop
-
نیاز Hypervisor به Schedule همزمان همه vCPUها
-
کاهش کارایی نسبت به VMهای کوچکتر
در بسیاری از سناریوها، دو VM ۸ هستهای کارایی بهتری از یک VM ۱۶ هستهای دارند.
1.4. ارتباط مستقیم عملکرد Hypervisor با معماری CPU
در سرورهای مدرن، انتخاب نوع پردازنده—از Intel Xeon Scalable تا AMD EPYC—مستقیماً بر عملکرد ماشینهای مجازی تأثیر دارد. پردازندههایی با تعداد Core بالا اما فرکانس پایین، برای بارهای Real-Time مناسب نیستند؛ برعکس، پردازندههای با فرکانس بالا و تعداد Core کمتر برای Workloadهای حساس بهترند.
2. معماری NUMA؛ ستون اصلی کارایی سیستمهای چندسوکتی
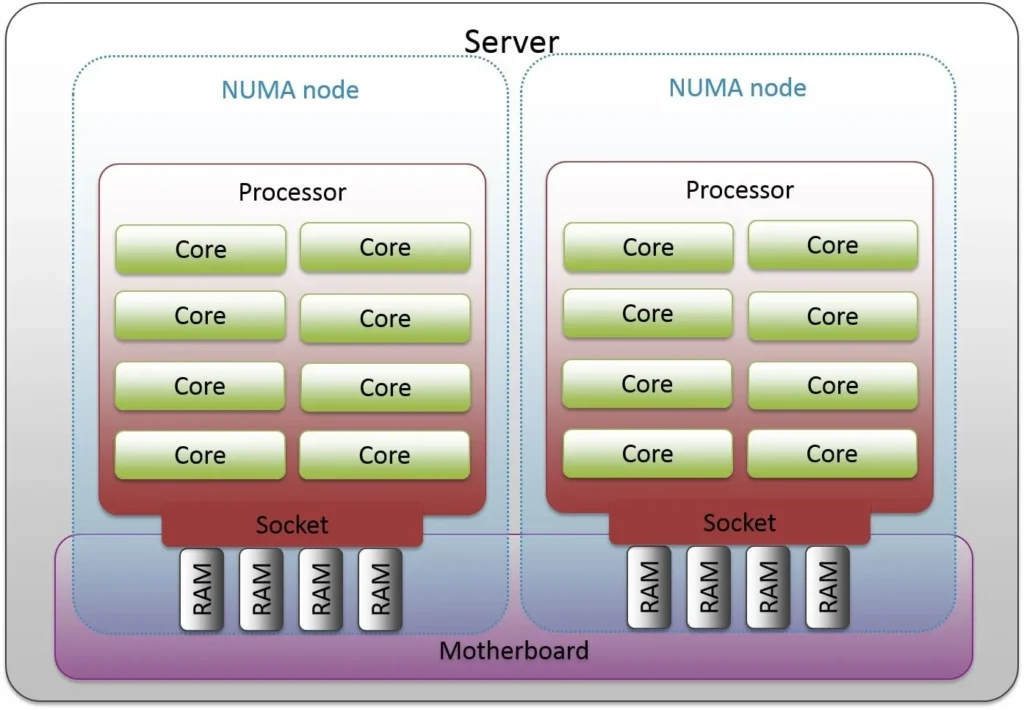
در سرورهای چندسوکتی و پردازندههای پیشرفته، معماری NUMA (Non-Uniform Memory Access) نقش بسیار مهمی در نحوه دسترسی هر CPU به حافظه ایفا میکند. NUMA تعیین میکند هر Thread یا VM از کدام بخش حافظه و روی کدام Node پردازشی اجرا شود.
2.1. چرا NUMA مهم است؟
NUMA Node شامل مجموعهای از:
-
یک CPU یا مجموعهای از Coreها
-
Memory Channelهای مستقیم مرتبط با آن CPU
است. دسترسی CPU به حافظه Local خود سریعتر از دسترسی به حافظه Node دیگر است. این اختلاف در بارهای سنگین باعث ایجاد تفاوتهای محسوس میشود.
2.2. مشکل رایج: VMهایی که NUMA Boundary را نقض میکنند
زمانی که یک VM بیش از ظرفیت یک NUMA Node باشد، Hypervisor مجبور میشود:
-
حافظه VM را بین چند Node توزیع کند
-
پردازش VM بهصورت Remote Memory Access انجام شود
نتیجه:
-
افزایش Memory Latency
-
کاهش کارایی پایگاهدادهها
-
ایجاد Bottleneck روی QPI/UPI در پردازندههای Intel
-
افزایش ترافیک XGMI در معماری AMD EPYC
در یک آزمایش عملی روی PostgreSQL، با قرار دادن VM در مرز صحیح NUMA، کارایی ۴۴٪ افزایش یافت.
2.3. اهمیت NUMA در VMهایی با vCPU زیاد
اگر VM شما:
-
بیشتر از ۸، ۱۲ یا ۱۶ vCPU دارد
-
نیاز به کارایی پایدار دارد
-
شامل سرویسهای Database یا Analytics است
طراحی NUMA آن باید بهصورت دستی انجام شود. VMware امکان NUMA-Aware Scheduling دارد، اما تنها زمانی اثرگذار است که VM از ابتدا صحیح طراحی شده باشد.
3. Firmware؛ لایهای حیاتی که بسیاری از Bottleneckها از آن آغاز میشود
Firmware واسط مستقیم بین سختافزار و Hypervisor است. هر نقص یا قدیمی بودن این لایه میتواند عملکرد کل سرور را مختل کند.
3.1. مؤلفههای Firmware مهم
-
BIOS / UEFI
-
Microcode پردازنده
-
Firmware کنترلرهای RAID / HBA
-
Firmware کارت شبکه
-
Firmware Backplane / Expander
-
BMC (iLO/iDRAC)
هر یک از این مؤلفهها بهصورت مستقیم روی:
-
عملکرد Storage
-
کارایی Network
-
سطح پایداری
-
رفتار Thermal و Power
-
سازگاری با Hypervisor
تأثیر میگذارند.
3.2. نمونههای واقعی مشکلات Firmware
در سرورهای قدیمیتر و حتی جدید، موارد زیر به دلیل Firmware اشتباه مشاهده میشود:
-
کاهش IOPS تا ۵۰٪ به دلیل باگ RAID Firmware
-
اختلال در NICهای Broadcom در ESXi 7
-
Rebootهای ناگهانی به دلیل Microcode معیوب
-
Packet Drop در کارتهای ۱۰/۲۵GbE
-
Memory Training ناکامل در BIOS قدیمی
در بررسی ۱۲۰ سرور در یک دیتاسنتر، مشخص شد ۷۲٪ مشکلات کارایی مستقیم به Firmware یا ناهماهنگی آن مربوط بوده است.
4. سرورهای HPE ProLiant؛ نقش پیکربندی صحیح در عملکرد واقعی سختافزار
سرورهای HPE ProLiant از پرفروشترین و پایدارترین سرورهای سازمانی هستند. قابلیتهایی مانند iLO، Smart Array و ابزارهای مدیریتی پیشرفته، آنها را به هسته زیرساخت بسیاری از دیتاسنترهای ایران و جهان تبدیل کرده است.
اما حتی این سرورها نیز هنگام پیکربندی نادرست، دچار افت کارایی میشوند.
4.1. Firmware در سرورهای HP اهمیت دوچندان دارد
سرورهای HP به شدت وابسته به هماهنگی Firmware هستند؛ بهخصوص:
Smart Array Firmware
کنترلرهای P408i، P816i، P440، P204i اگر Firmware آپدیت نباشد:
-
Queue Depth محدود میشود
-
Latency افزایش مییابد
-
عملکرد RAID 5/6 افت شدید پیدا میکند
در یک پروژه، با آپدیت Smart Array Firmware، سرعت Random Write تا ۲.۱ برابر بهتر شد.
iLO Firmware
iLO علاوه بر مدیریت، سیستم Thermal و Power را کنترل میکند. نسخههای قدیمی آن گاهی باعث:
-
افزایش غیرطبیعی Fan Speed
-
هشدارهای اشتباه دمایی
-
افزایش مصرف انرژی
میشوند.
سرویس SPP (Service Pack for ProLiant)
HPE SPP مجموعهای هماهنگ از Firmware و Driver است. استفاده از نسخه ناسازگار ممکن است باعث:
-
عدم شناسایی RAID
-
Crash Hypervisor
-
اختلال در NICهای FlexLOM
شود.
4.2. NUMA در سرورهای HPE: Intel vs AMD
پردازندههای Intel در DL380/DL360
-
یک NUMA Node برای هر CPU
-
دسترسی به حافظه Local سریع است
-
Cross-node از UPI انجام میشود
پردازندههای AMD EPYC در DL325/DL385
-
دارای NUMA Nodeهای بیشتر
-
حساسیت بالاتر به NUMA Alignment
-
عملکرد VMهای سنگین وابسته به طراحی NUMA است
در محیطهای مبتنی بر DL385، تنها با اصلاح NUMA، ماشینهای SQL Server تا ۵۵٪ بهتر عمل کردند.
4.3. Hypervisor بر روی سرورهای HP: نکات کلیدی
-
ESXi نسخه HPE Custom Image برای نصب توصیه میشود
-
Driverهای مخصوص Smart Array باید نصب شوند
-
Memory Interleaving در BIOS باید درست تنظیم شود
-
Power Profile باید روی Maximum Performance یا OS-Controlled باشد
-
BIOS Mode بهتر است UEFI باشد برای کارایی بهتر
5. جمعبندی نهایی: پیکربندی صحیح، مهمتر از خرید سختافزار جدید
تحلیلهای فنی و تجربیات واقعی نشان میدهد:
-
بیش از ۶۰٪ مشکلات کارایی ناشی از پیکربندی اشتباه است
-
تنها ۱۵٪ مشکلات مربوط به محدودیت سختافزار است
-
اصلاح NUMA، vCPU و Firmware میتواند کارایی را تا ۲ برابر افزایش دهد
سرورهای HPE ProLiant از قدرتمندترین پلتفرمهای بازار هستند، اما تنها با پیکربندی صحیح Hypervisor، NUMA و Firmware است که پتانسیل واقعی آنها آزاد میشود.
